Microservices using NestJS
As a backend developer, I was always fascinated by microservices, dreaming of joining a big team where we use cutting-edge stuff to solve real-world problems.
There are many guides on the internet written by professionals, I wanted to try something and share it with you.
Introduction
Microservices
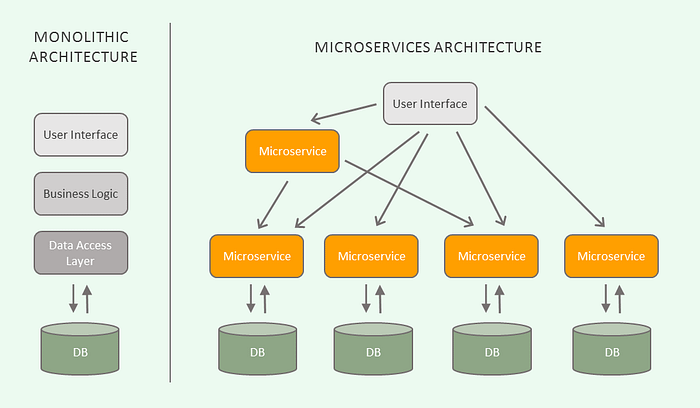
Microservices are an architecture and organization method for software development, in which software consists of small independent services that communicate through APIs.
Here is a great source to learn more about it.
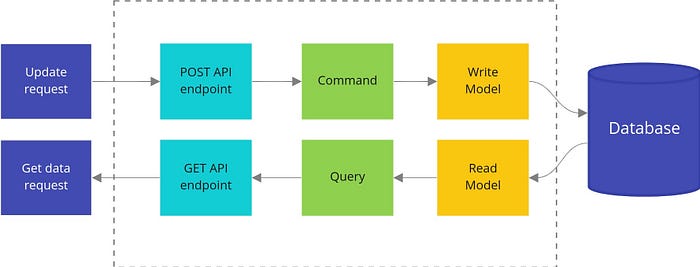
CQRS
CQRS (Command and Query Responsibility Segregation) is a pattern that separates the read and updates operations of data storage, implementing it in your application can maximize its performance, scalability, and security. The flexibility that comes with migrating to CQRS allows the system to evolve better over time and prevents update commands from causing merge conflicts at the domain level.
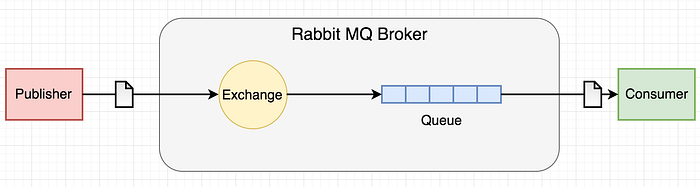
RabbitMQ
RabbitMQ is lightweight and easy to deploy locally and in the cloud. It supports multiple messaging protocols. RabbitMQ can be deployed in distributed and federated configurations to meet large-scale, high-availability requirements.
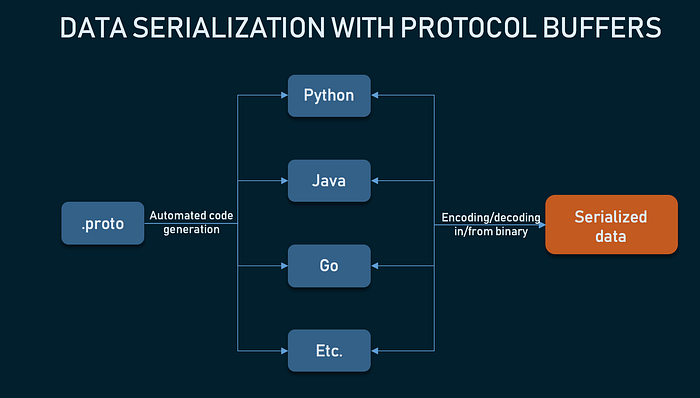
GRPC
gRPC is a modern open-source high-performance remote procedure call (RPC) framework that can run in any environment. It can effectively connect services within and between data centers through pluggable support for load balancing, tracking, health checks, and authentication. It also applies to the last mile of distributed computing, connecting devices, mobile applications, and browsers to back-end services.
My Approach
We have 4 services (Customers, Products, Order, Source) and a Gateway.
hint: Microservice is meant to be used on large-scale software, for the sake of demonstration I did pick a small one.
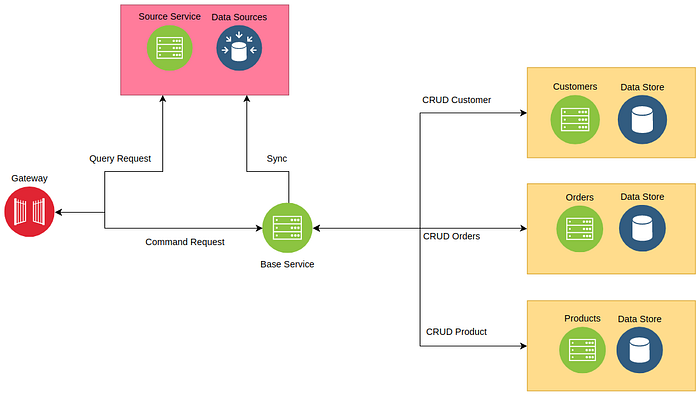
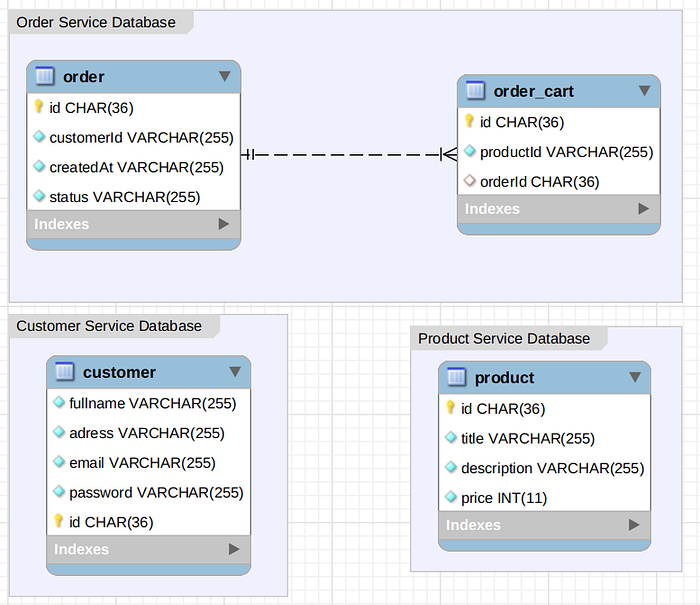
The Customers, Products, Order Services have a MySql database for each one of them, While the Source Service has a MongoDB database.
When a user registers himself, the request will pass by the Base service this later will be forwarded to the Customers service, then a response is returned, if it is accepted then Base service will forward the new customer to the Source Service to sync the content, either it is accepted or rejected the response will be forwarded to the client. this process is the same for when we try to do POST/PUT/DELETE on Customers, Products, Order.
Except for orders, it has an extra step, that is on order success when the response is returned to Base service, this later will send the customerId to Customer Service to get the whole customer information, and send all the product Ids to the Product Service as a single request then this later will return an array that has for each ID the whole product information, the Base Service will aggregate the content to produce an object that has everything.
This extra step is needed to prevent doing joins each time we request an order, therefore, saving computation and latency at a cost of disk space.
GET orders requests (getAll/getById) pass directly to Source Service.
The other developers would store the other services (Customer, Product) content in Source Service, where I only store data (Orders) that need to be joined to make sense of it for the frontend.
For in services communication both:
RabitMQ pushes messages to a queue asynchronously and ensures they are delivered to the correct destination with the correct order,
And gRPC to make a faster message exchanging.
e.g: Base Service sending new customer data to Customer Service.
All Services do implement them both except for the gateway in which is a regular Restful API.
With all that being said, one of the main reasons to adopt the microservices is for its fault tolerance, as if any services do go down then the whole system would not go fall apart.
If the Customer Service does fall, then the client will still be able to retrieve the product and order list, same for Product/Order respectively.
if all Customer, Product, and Order Services even the Base Service does fall, then only the order list will be displayed as it is stored into the Source Service.
If the source service does fall then we can do something like fall back to the traditional approach by requesting information from all services and doing SQL join and data aggregation.
Both Gateway and Base Service are critical services, but they also have a simple role, to forward and redirect requests/responses, therefore, giving a low chance for them to fail, unlike the other service in which they do some sort of computation and data storing.
Implementation
NestJs is a progressive Node.js framework for building efficient, reliable, and scalable server-side applications.
All our services and the gateway app are made by the CLI:
nest new customer-serviceIn addition, these packages will enable microservices capabilities in NestJs along with protobuf and AMQP support:
yarn add @nestjs/microservices ts-protoc-gen@next amqplib amqp-connection-managerFor the services that use MySQL, we will use this package @nestjs/typeorm and for the Source Service we will use @nestjs/mongoose.
Let’s implement the customer services, and it gonna be same for the Product and Order Services.
We will start by registering the RabbitMQ, the main.ts file should be like this:
Next we define the customer entity as follow:
We need to link the service with the RabbitMQ and the database, the app.module.ts should be like this:
Our Controller will be as follow:
Let discuss the controller, as you might see the decoraters that we are using are no longer HTTP verbs instead we are using MessagePattern we pass message that we want to subscribe, don’t worry about CustomerItem we will talk more about it for now it is just a serialized proto that is given by the Base Service.
About the app.service.ts it is as regular as you used to build before, it has implemented function that the controller use.
That it for the Customer Service it is the same for the other services (Product, Order)
Now let’s talk about the Source Service specially the app.service.ts file:
When the service is up, it will start with onModuleInit() function that will clear the mongo database, then it get’s all product/customer ids (if a faulty request that hold wrong id, it will be rejected), finally the buildOrdersMap() function will request orders along with the respective product and ids, to build the data as we did talk in the previous section.
When an order is issued it will check the product/customer id for duplication and availability. Then we send the order request to the Order Service if on success then we send ids on patchCustomer and patchProducts to get the full data.
Now we will talk about Base Service, this later has module for each service, and it is easy to implement:
Finally the Gateway, as I said it is a regular nestJs app that you used to build, and it has like Base Service a module for each one, main.ts file:
The only new thing is the proto file:
Then we need to generate it using the below command:
protoc \
--plugin="protoc-gen-ts=./node_modules/.bin/protoc-gen-ts" \
--js_out="import_style=commonjs,binary:." \
--ts_out="." \
src/protoData/customer.protoTo be able to read the proto file, you need to add this in nest-cli.js for each services:
"compilerOptions": {
"assets": ["**/*.proto","**/*.js"],
"watchAssets": true
}Finally export the generated files to the appropriate service for deserialization.
controller:
service:
I hope you enjoy reading my article if you have some points to add or to correct feel free to write comments, peace.